函数式编程
与面向对象、过程式编程并列的编程范式
- 函数是一等公民
- 强调将计算过程分解成可复用的函数,典型例子:
map和reduce组合的MapReduce算法 - 函数是一种数学运算,要求必须是纯粹的,
函数式编程的起源是一门叫做范畴论(Category Theory)的数学分支
什么是范畴呢?
In mathematics, a category is an algebraic structure that comprises “objects” that are linked by “arrows”.
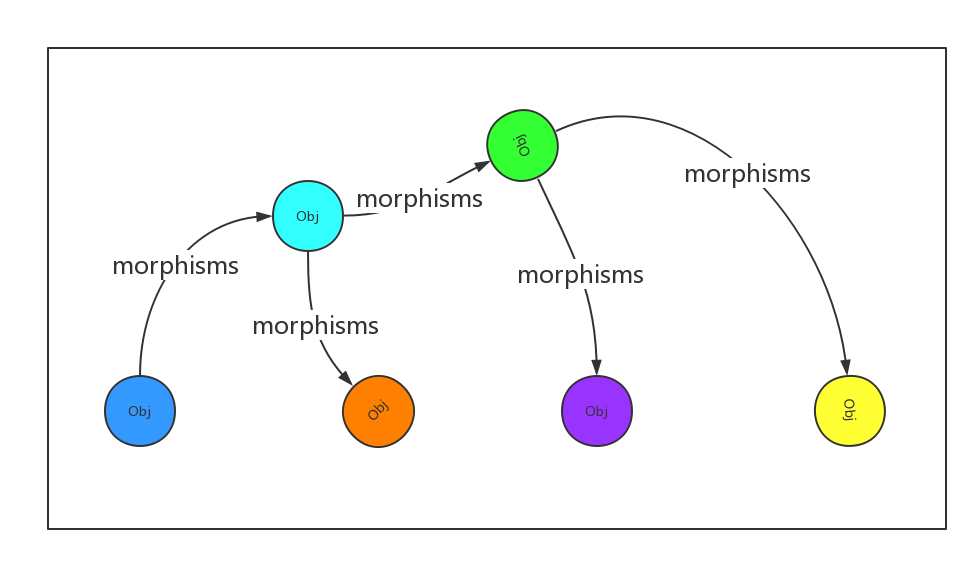
箭头表示范畴成员之间的关系,正式名称为“态射”(morphism)范畴论认为,同一个范畴的所有成员,就是不同状态的“变形”(transformation)。通过“态射”,一个成员可以变形成另一个成员。
范畴的数学模型
- 所有成员是一个集合
- 变形关系是函数
也就是说,范畴论是集合论上的抽象,简单的理解就是“集合+函数”
理论上通过函数,范畴中的成员可以算出其他所有成员。
范畴与容器
- 值(
value) - 值的形变关系(
function)
- 范畴论与函数式编程的关系
- 范畴论使用函数表达范畴之间的关系。
- 伴随范畴论的发展,就发展出一整套函数的运算方法。这套方法起初只用于数学运算,后来有人将它在计算机上实现了,就成了“函数式编程”
- 本质上函数式编程只是范畴论的运算方法,跟数理逻辑、微积分、行列式是同一类东西,都是数学方法,只是能用来写程序
函数的合成(compose)
函数合同满足结合律
1 | // 参数个数相同 |
函数的柯里化
把一个多参数的函数,转化为单参数函数
1 | // 柯里化之前 |
函数常规方法
1 | @FunctionalInterface |
Java Lambda
简述Java Se 8中新引入的Lambda语言特性以及这些特性背后的设计思想
Lambda表达式- 方法引用 & 构造器引用
- 拓展的目标类型 & 类型推导
- 接口中的默认、静态方法
Backgroud
面向对象编程使用带有方法的对象封装行为,函数式编程使用函数封装行为。
Java的对象比较重量级,实例化一个类型会涉及不同的类型,并需要初始化字段和方法。
Java有时会封装单函数对象,例如Runnable、ActionListener等
1 | public interface Runnable{ |
此处并不需要专门定义一个类来实现Runnable,一般会使用匿名类型内联
1 | new Thread(new Runnbal(){ |
并行领域是个值得研究的领域,因为摩尔定律在此得到了重生,尽管没有更快的CPU,但是有更多的CPU,串行API就只能使用有限的计算能力
随着函数式编程风格的流行,Java需要提供一种尽可能轻量级的封装方式(model code as data),匿名内部类并不是一个好的选择
- 语法过于冗余
- 内部类的
this和外部容易使人误解 - 类型载入和实例创建语义不够灵活
- 无法捕获非
final局部变量 - 无法对控制流程进行抽象
以上多数问题均在Java Se 8中得到了解决
- 通过提供更简洁的语法和局部作用域规则,解决了问题1 & 2
- 通过提供更加灵活便于优惠的表达式语义,绕开了问题3
- 通过允许编译器推断变量的“常量性”,减轻了问题4
函数式接口
@FunctionalInterface
每一个函数对象对应一个接口类型,便于和Java类型系统紧密结合。
- 接口是Java类型系统的一部分
- 接口天然就拥有运行时表示(Runtime representation)
- 接口可以通过Javadoc注释来表达一些非正式的协定
编译器会通过@FunctionalInterface注解来判断且检查是否满足函数式接口的要求
Java并没有引入了一个全新的结构化函数类型,而是选择了“使用已知类型”,因为现有的类库大量使用了函数式接口,我们可以用lambda表达式直接实现现有类库。Java Se 7中已存在的函数式接口:
java.lang.Runnablejava.util.comcurrent.Callablejava.security.PrivilegedActionjava.util.Comparatorjava.io.FileFilterjava.beans.PropertyChangeListener
Java Se 8 新增加了一个包,java.util.function包含了常用的函数式接口:
Predicate<T>,接收T返回booleanConsumer<T>,接收T,无返回Function<T,R>,接收T,返回RSupplier<T>, IntSupplier<T>,提供T(工厂),无参UnaryOperator<T>,接收T,返回TBinaryOperator<T>, LongBinaryOperator<T>,接受两个T,返回TBiFunction<T,U,R>,接收T, U,返回R
Lambda Expressions
匿名类型最大的问题就其冗余的语法,lambda表达式提供了轻量的语法,解决了“高度问题”。
1 | (parameters) -> expression / statement || (parameters) -> {statements} |
Target typing
函数式接口的名称并不是Lambda表达式的一部分,Lambda表达式的类型由上下文推导得出。
相同的Lambda表达式在不同的上下文中拥有不同的类型
1 | Callable<String> c = () -> "hello world"; |
编译器利用上下文所期待的类型推导Lambda表达式的类型,所期待的类型就是目标类型,Lambda表达式只能出现在目标类型为函数式接口的上下文中。
Lambda表达式对目标类型也是有要求的,编译器会检查Lambda表达式的类型和目标类型的方法签名是否一致,当且仅当以下所有条件均满足时,Lambda表达式才可以被赋值给目标类型F
F是一个函数式接口- Lambda表达式的参数和
T的方法参数在数量和类型上对应 - Lambda表达式的返回值和
T的方法返回值兼容 - Lambda表达式所抛出的异常和
T的方法throws类型兼容
Lambda表达式的参数类型可以从目标类型中推导出, 当只有一个参数时括号可省略
1 | Comparator<String> c = (x, y) -> x.compareTo(y); |
泛型方法调用和<>构造器调用也通过目标类型进行类型推导
1 | List<String> list = Collections.emptyList(); |
目标类型的上下文
带有目标类型的上下文如下:
- 变量声明
- 赋值
- 返回语句
- 数组初始化
- 方法和构造器参数
- Lambda表达式的函数体
- 三元运算符
- 转型表达式
1 | Comparator<String> c = (x, y) -> x.compareTo(y); |
方法参数的类型推导会涉及:重载解析 & 参数类型推导。
当Lambda表达式作为方法参数时,重载解析会影响到Lambda表达式的目标类型。当Lambda表达式显式指定参数类型,编译器可以直接使用返回类型,当Lambda表达式的参数类型推导得出,重载解析会忽略函数体而只依赖表达式参数数量。
如果解析方法声明时存在二义性,则需要使用转型或显式Lambda表达式来提供更多的类型信息。
1 | Stream<String> s = list.stream().map(x -> x.getName()); |
- 显式Lambda表达式参数类型
- Lambda表达式转型为
Function<T,R> - 为泛型参数提供一个实际类型,
.<String>map(x -> x.getName()
Lambda表达式可以通过外部的目标类型推导出内部的返回类型,可以方便的编写返回函数的函数
1 | Supplier<Callable<String>> s = () -> () -> "hello world"; |
目标类型不仅适用于Lambda表达式,泛型也收益。
1 | List<Integer> list = Collections.checkedList(new ArrayList<>(), Integer.class) |
词法作用域
内部类中使用变量容易出错,继承的成员可能会把外部类的成员掩盖,未限定的this引用会指向内部类
相对于内部类,Lambda表达式的语义就十分简单,它不会继承super,也不会引入新的作用域。Lambda表达式基于词法作用域,其内外具有相同语义(如for循环一致)
变量捕获
在Java Se 7中,编译器对内部类中引用的外部变量(即捕获的变量)要求必须声明为final,在Java Se 8中放宽了限制,对于Lambda表达式和内部类,允许在捕获有效只读的变量(本质上仍然是final,只是不用显式声明)
对this的引用,以及通过this对未限定字段、方法的引用在本质上都是调用final局部变量,当引用this时相当于捕获了this实例,其他情况下,不会保留任何对this的引用。
内部类实例会一直保留一个对外部类实例的强引用,而没有捕获this的Lambda表达式则不会保留其引用,避免造成内存泄漏。
Lambda表达式不支持修改捕获变量的另一个原因是可以使用规约来实现同样的效果。java.util.stream包提供了多种规约操作(如sum、min、max等)
1 | int sum = list.stream().mapToInt(x -> x.size()).sum(); |
方法引用
隐式
Lambda表达式
Lambda表达式允许定义一个匿名方法以及以函数式接口的方式使用,希望能够在已有的方法上实现同样的特性。
方法引用与Lambda表达式具有相同的特性(目标类型 & 函数式接口),可直接通过方法名称引用已有的方法
1 | Comparator<String> c = Comparator.comparing(String::toString); |
String::toString可被看成Lambda表达式的简写,方法引用不会将语法变得更紧凑,但拥有更明确的语义(可通过方法名直接调用)
1 | Consumer<Integer> c1 = System::exit // void exit(int status) |
方法引用种类
- 静态方法引用
ClassName::method - 实例上的实例方法
ref::method - 超类上的实例方法
super::method - 类型上的实例方法
ClassName::method - 构造方法
ClassName:method - 数组构造方法
TypeName::new
1 | Predicate<String> p = list::contains; |
一般不需要指定方法引用的参数类型,编译器可以推导出结果,但如果需要可以在::之前显式提供参数类型。
1 | IntFunction<int[]> f = int[]::new; |
默认方法 & 静态方法
Lambda表达式和方法引用提升了Java语言的表达能力,为了把代码即数据(code as data)变的更加容易,需要将这些特性融入到已有的库中。
默认方法(被称为虚拟拓展方法或守护方法)的目标式解决在已有的类库增加功能,使得接口在发布之后仍能被逐步演化。
默认方法利用面向对象的方式向接口增加新的行为,接口方法可以是抽象的或默认的。默认方法拥有其默认实现,实现接口的类型通过继承得到该默认实现(如果类型没有覆盖该默认实现)。默认方法不是抽象方法,所以可以向函数式接口中增加默认方法。
如下展示如何向Iterator接口中增加默认方法skip
1 | interface Iterator<E>{ |
以上Iterator定义,所有实现Iterator的类型都会继承skip方法,子类可以通过覆盖skip来提供更好的实现(移动游标或提供原子性操作等)
当接口继承其他接口时,既可以为所继承的抽象方法提供一个默认实现,也可为继承而来的默认方法提供一个新实现或把继承来的默认方法抽象化。
除了默认方法,Java Se 8还允许在接口中定义静态方法,这使得我们可以从接口直接调用和它相关的辅助方法,而不是从其它的类中调用(之前此种类对应的接口的复数命名,如Collections)
1 | public static <T, U extends Comparable<? super U>> Comparator<T> comparing(Function<T, U> f){ |
继承默认方法
和其他方法一样,默认方法也可以被继承,大多数情况下继承行为和期待的一致。不过,当类型或接口的超类拥有多个具有相同签名的方法时,我们就需要一套规则来解决此冲突。
- 类的方法声明优先于接口默认方法
- 被其他类型所覆盖的方法会被忽略(适用于
super共享一个method的情况)
为了演示第二条规则,假设Collection和List接口均提供了removeAll的默认实现,然后Queue继承并覆盖了Collection中的默认方法,在下面的implements从句中,List中方法声明会优先于Queue中的方法声明。
1 | class LinkedList<E> implements List<E>, Queue<E> |
当独立的默认方法相冲突或默认方法和抽象方法相冲突时会产生编译错误。此时需要显式覆盖父类方法。一般会定义一个默认方法来显式选择父类方法。
1 | interface X implements Y, Z { |
在设计Lambda时的一个重要目标就时新增的语言特性和库特性能够无缝结合。
1 | Collections.sort(list, new Comparator<User>(){ |
Stream
A sequence of elments supporting sequential and parallel aggregate operations.
映射方法
filtermaplimitdistinct(依赖equals方法)
归纳方法
countcollect
1 | list.stream().filter(x -> x.getAge() > 3).map(x -> x.getName()).collect(Collectors.toList()); |
串行流 & 并行流
1 | // 串行流 |
使用并行只需要parallel()即可
并行内部将数据分成多段,每段一个线程并行处理,然后join一起输出
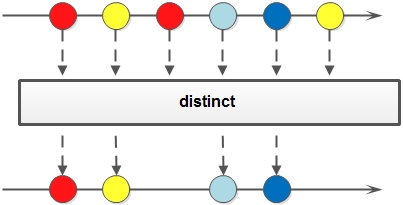
distinct,对stream中包含的元素去重(依赖equals)
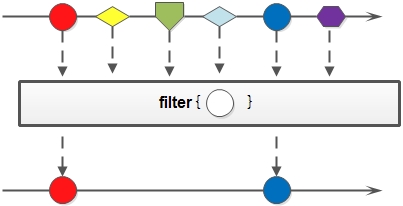
filter,对stream中包含的元素使用给定的过滤函数进行过滤
map,对stream中包含的元素使用给定的转换函数进行转换操作,jdk有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong,mapToDouble,可以避免自动装、拆箱的消耗。
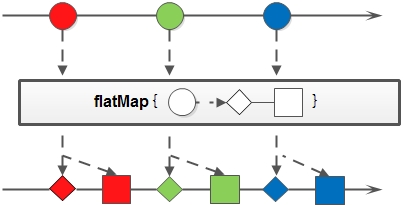
flatMap,与map类似,不同的是每个元素转换得到的是stream对象,会把子stream中的元素聚合到外部父集合中
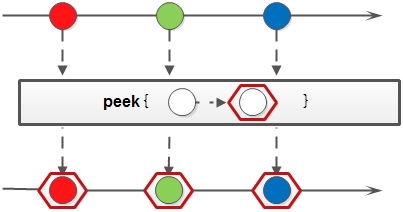
peek,生成一个包含原stream的所有元素的新stream,同时会提供一个消费函数Consumer实例,新stream元素被消费的时都会调用给定的Consumer函数
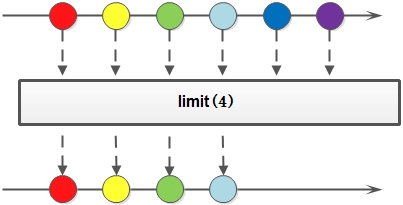
limit,对于一个stream进行截断操作,获取其前N个元素,如果元素个数不足N,返回所有元素
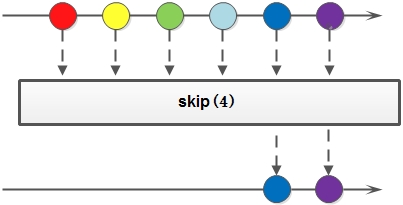
skip,返回一个丢弃N个元素后的新stream,如果元素个数不足N,返回空stream
stream的操作都是lazy的,内部会依赖转换函数生成新的函数(不执行),在reduce时遍历stream,每个元素都执行新的函数。
Reduce
可以简单的理解为归纳结果方法
reduce可以分为两种
- 可变归纳,将元素归纳到可变容器中,如
Collection或StringBuilder - 其他归纳,除去可变都时其他,一般都是通过前一次归纳的结果当作下一次的入参,如
reduce、count、allMatch
可变归纳
只有一个方法collect
1 | // supplier是一个工厂函数,生成容器 |
以下提供collect另外一个重写版本(依赖Collector)
1 | <R, A> R collect(Collector<? super T, A, R) collector); |
Java Se 8提供了工具类Collectors
1 | List<String> l = s.stream().filter(x -> null != x).collect(Collectors.toList()); |
其他归纳
reduce方法非常通用,简单介绍其最常用的两种重写方式
1 | Option<T> reduce(BinaryOperator<T> accumulator); |
reduce有一个常用的变种
1 | T reduce(T identity, BinaryOperator<T> accumulator); |
查询相关
allMatch,是否所有元素都满足anyMatch,任意元素是否满足findFirst,返回首个元素noneMatch,是否所有元素均不满足max&min,使用给定的Operator计算值

